Pixel Jump CS 175: Project in AI (in Minecraft)
Video
Project Summary
Some minor changes have been made to the proposed ideas to enhance the creativity and interest of our project. Instead of keeping the platforms in a fixed size (3x3), we added a 1x1 size platform type. The reward of stepping on the 1x1 size platform is the same as stepping on the center block of a 3x3 size platform In addition, we successfully simulated the jumping mechanism of the original game in the minecraft world. A mission generator is implemented to randomly generate platforms for a mission. Our agent can perceive the environment through the states which includes the x, y, z coordinates and its velocity. Our following goal is to complete the implementation of tabular Q-learning algorithms.
Approach
Environment & Reward System
Jumping platform Center: +100
Other area of platform: +10
Lava: -10
State Space
\((s^3)(n-1)\)
\(s:\) the max side size of among the platforms (s = 3 for 3x3 platforms)
\(n:\) the number of platforms
Action Space
Our action space is a new implementation based on teleport to achieve the action of projectile motion of jumping. Here are the equations we used for constant gravitational acceleration:
Classical Mechanics
\(\begin{align} &Horizontal\,(x), \,\,\,\,a_x = 0\, &Vertical\,(y), \,\,\,\,a_y = -g \\ \hline &V_x = V \cdot cos\theta\, &V_y = V \cdot sin\theta + a_y \cdot \Delta t \\ &\Delta x = V_x \cdot \Delta t\, &\Delta y = V_y \cdot \Delta t + \frac{1}{2} \cdot {\Delta t}^2 \\ \end{align}\)
This is a matrix we will be storing in order to send corresponding commands to perform projectile motion. \(\begin{bmatrix} X & v_x \\ Y & v_y \\ Z & v_z \end{bmatrix}\\), where X, Y, Z denotes the position of the agent and their velocity according to its axis.
Here is our implementation:
def movement (v, x ,y):
ax = 0
ay = -9.8
t = 0.08
d = np.radians(70)
M = []
vx = v * np.cos(d)
vy = v * np.sin(d)
while True:
x = x + vx*t
y = y + vy*t + 0.5*ay*(t**2)
vx = vx + ax*t
vy = vy + ay*t
if y < FLOOR:
break
M.append([x,y])
return M
Machine Learning Algorithms
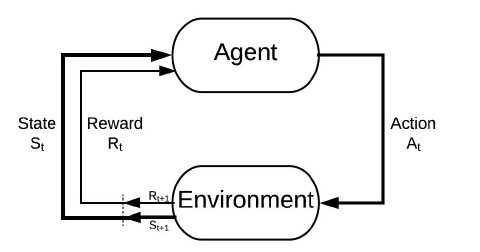
The main algorithm that we used is using tabular Q-learning to train our jumping agent. According to the lecture materials, the Q-Learning Algorithm:
\(\begin{aligned}
&Q(S_t, A_t)\leftarrow Q(S_t, A_t) + \alpha[R_{t+1} + \gamma\max_a Q(S_{t+1},a)- Q(s_t, A_t)]
\end{aligned}\)
\(S_t:\) current state
\(A_t:\) current action
\(Q(S_t, A_t):\) old values
\(\alpha:\) learning rate
\(R_{t+1}:\) reward
\(\gamma:\) discount factor
\(\max_a Q(S_{t+1},a):\) estimate of optimal future value
\(R_{t+1} + \gamma\max_a Q(S_{t+1},a)- Q(s_t, A_t):\) temporal difference
Evaluation
Quantitative
Since the reinforcement learning algorithm is only partially deployed. Currently, we don’t have an accurate measurement of the quantitative values. We thus do not have any graphs to showcase. However, the environmental feedback such as rewards has been established. The agent receives +1 after landing on the non-center block. Landing on the center block rewards the agent with +5. And falling to lava will deduct the reward score by 10. Earning a positive score at the end of the mission signifies that the agent has either reached at least 10 blocks or has reached at least a center block without failing. In addition to gain a further comprehension of the agent’s learning process, we plan to plot its chosen velocities of each state to see how well it is learning and to prevent overfitting. The rewards are subject to be changed.
Qualitative
As for qualitative evaluation, the simplest method to examine the overall quality of the project is to watch the agent’s movement and achievement. By watching the movements of the agent, we can make assumptions about whether the agent is choosing movements at random or it is advancing itself. By seeing how far the agent can make us an intuitive conclusion of the performance of the agent.
Remaining Goals and Challenges
The current limit of our project is not the algorithm itself but the implementation of the algorithm. We are still in the initial stage of implementing the Q-learning algorithm. We are currently trying to figure out the optimal form of states and the ways to integrate states with Q-learning algorithms. This is the remaining goal of the project. We will schedule an appointment with our mentor to discuss this. A possible challenge we will face is being unable to meet on a regular basis weekly since we are all in different time zones.
Resources Used
Malmo
Physics
- Classical Mechanics
- Physics: Projectile Motion
- Verifying proper displacement range for particular velocity
Machine Learning Algorithm